How the Network Technology team reacts to server overloads – from automated alerts to manual intervention and long-term optimization.
Servers under our IT support are monitored in real time using professional monitoring systems. We continuously observe CPU, RAM, disk operations and network traffic. When any parameter exceeds its threshold, an alert is triggered automatically.
This happens even before real users notice an issue — our goal is proactive protection and fast response.
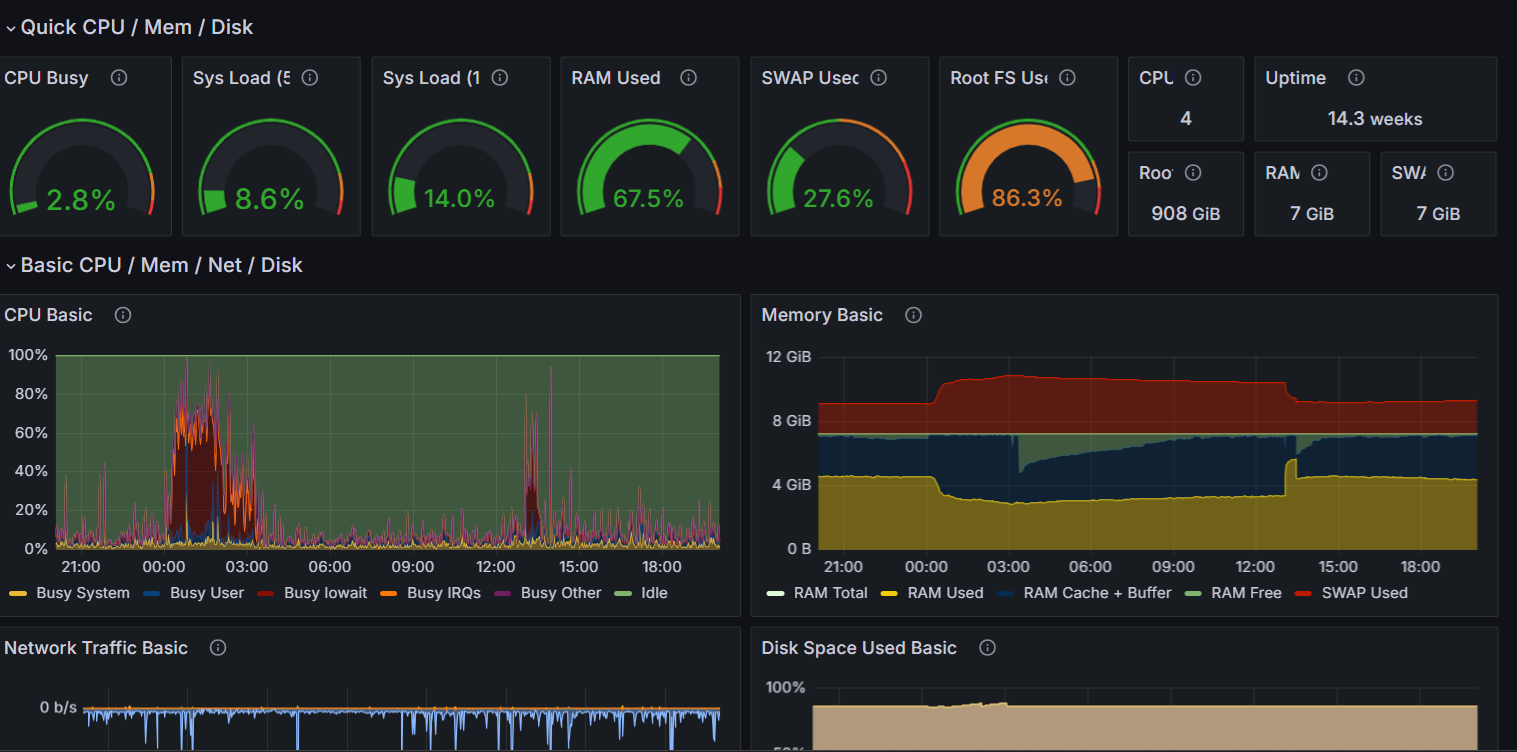 Example of a real alert during high server load
Example of a real alert during high server load We receive alerts in real time via Telegram, email and our centralized monitoring system. Thanks to this connectivity, we react immediately — long before the client experiences an issue. Once an alert is triggered, we verify whether the cause is temporary load, malicious activity or a faulty script.
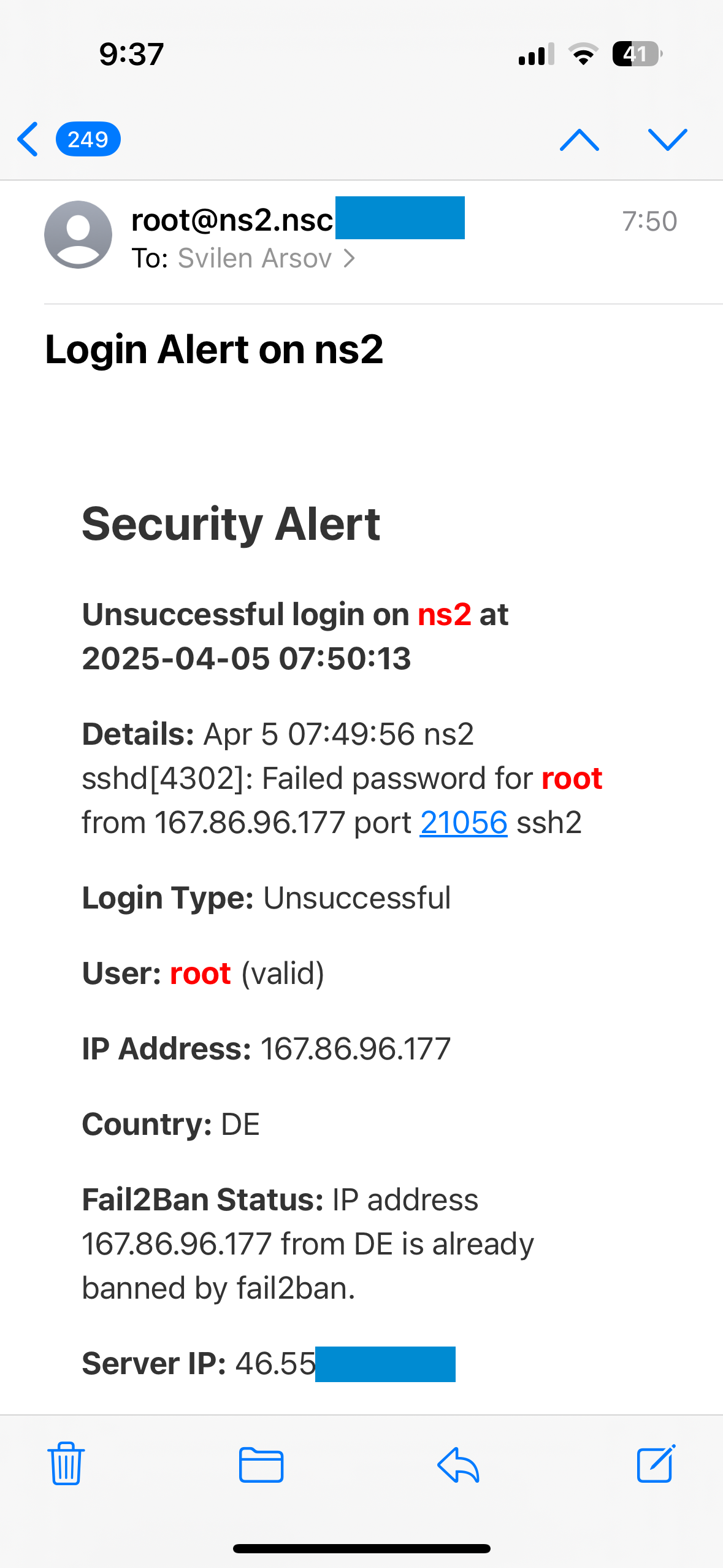
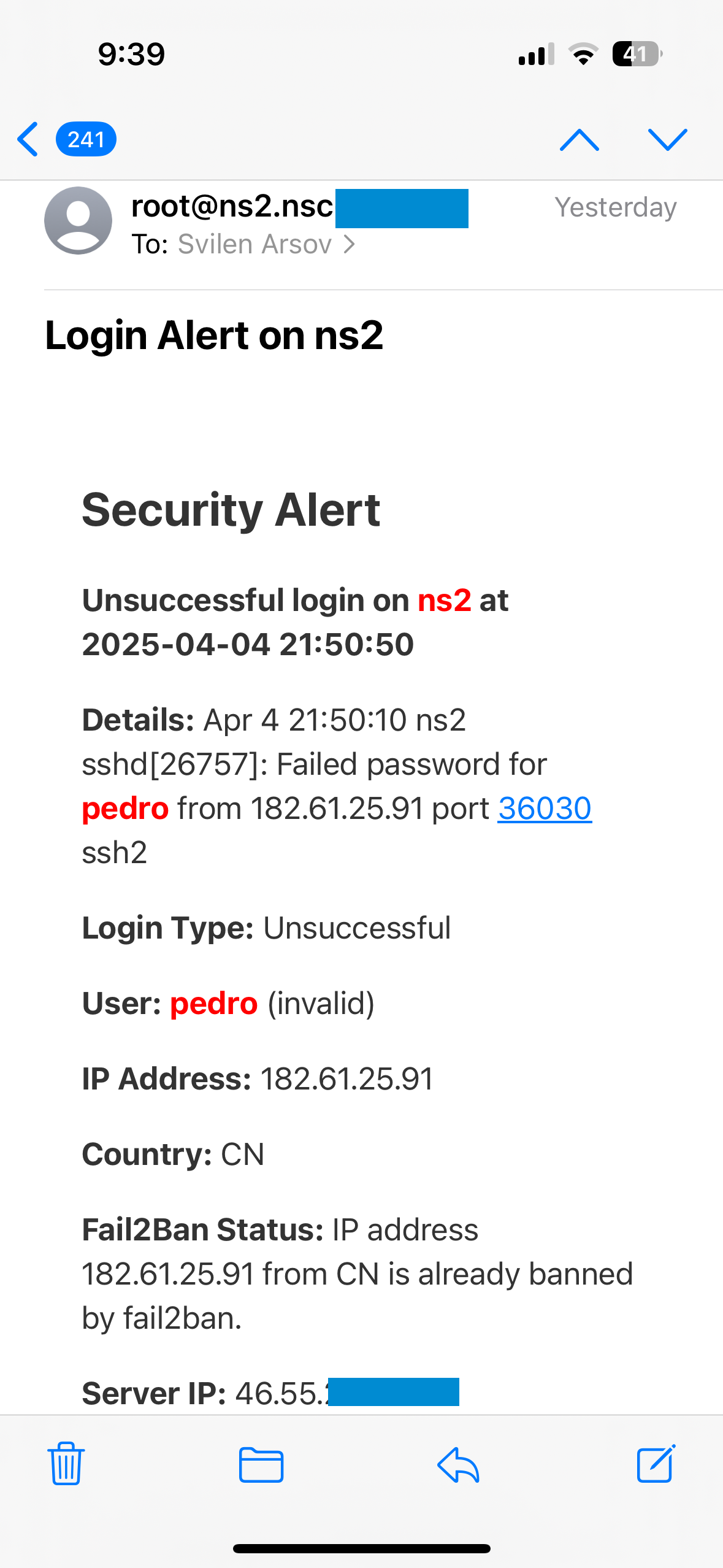
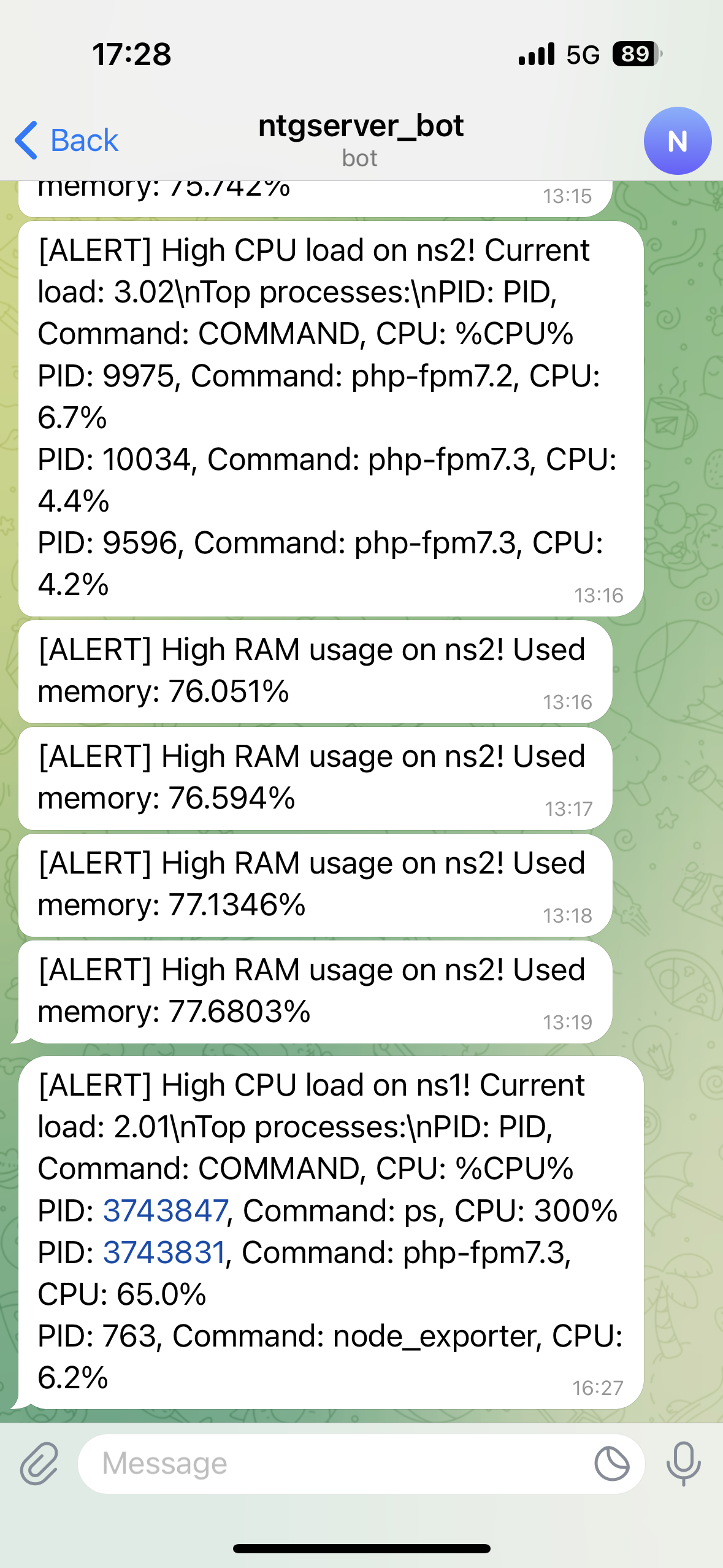
The system can automatically stop a process, restart a service or clear cache. When needed, one of our system administrators intervenes manually. Reaction time is usually within minutes, thanks to our IT consultations and automation processes.
After stabilizing the situation, we analyze logs, processes and traffic. We check whether the problem was a one-time event or a recurring issue — for example, an unrestricted cron job, bot traffic or a misconfiguration. We don’t just fix the symptom — we find and resolve the root cause.
Based on our analysis, we provide optimization recommendations such as:
When the system begins to struggle, we’ve already taken action. We don’t wait for the site to go down — we prevent it before it happens. Our approach is proactive, precise and timely, because stability is the foundation of trust.
If you are looking for professional IT support with guaranteed response time and security, contact us today.